
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Yolo5 custom dataset
- scenedelegate
- Kafka
- Yolo5
- opencv
- Apache Spark
- 준지도학습
- 스파크
- caffemodel
- Swift
- roboflow
- 내채공만기
- yolov5
- face blur
- 앱생명주기
- Apache Kafka
- YOLO
- 카프카
- SeSAC
- IOS
- 비식별화
- 파이썬
- python
- train data
- 아파치 스파크
- 내일채움공제만기
- 얼굴 비식별화
- iOS부트캠프
- 아파치 카프카
- SPARK
- Today
- Total
봉식이와 캔따개
머신러닝 데이터셋 종류 (train, validation, test) 본문
Train Data
-
모델을 학습시키기 위한 Data
-
Train data를 이용해 각기 다른 모델을 서로 다른 epoch로 학습시킨다
(epoch : 전체 Data set에 대해 한 번 학습을 완료한 상태)
-
모델을 학습하는 데에는 Train data만 사용한다
Validation Data
-
학습이 이미 완료된 모델을 검증하기 위한 Data
-
모델을 학습시키지 않는다
-
학습시키지는 않지만 학습에 관여한다
Test Data
-
학습과 검증이 완료된 모델의 성능을 평가하기 위한 Data
-
학습에 전혀 관여하지 않고 최종 성능을 평가하기 위해 쓰인다
Validation Data의 역할

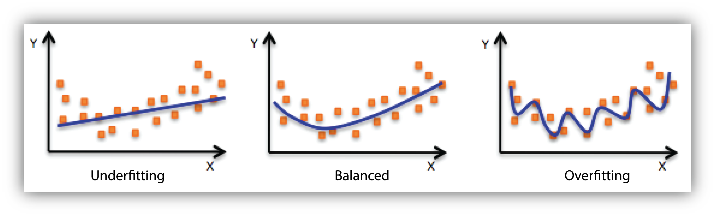
그림에서 우측으로 갈 수록 epoch를 늘려가면서 train data를 학습시키는 과정이다.
가운데 그림은 train data 뿐 아니라 일반적인 data에 대해서도 좋은 성능을 보인다.
맨 우측 그림을 보면 train data에 과적합되어 다른 data에는 안좋은 성능을 보일 것이다.
즉 train data로 학습을 할 때 너무 높은 epoch를 주면
train data에 대해서는 매우 높은 성능을 보이지만, 학습될 때 사용되지 않은 데이터 셋에 대해서는 정확도가 떨어지는 과적합 문제가 발생하는 것을 알 수 있다.

Validation data는 이런 과적합 문제를 막기 위한 data이다.
위 그림은 Validation data를 사용하여 train data에 대한 epoch값을 바꿔가며 error 곡선을 그린 모습이다.
파란 점선에서 멈추는게 적당해보인다.
이러한 방식으로 적절한 epoch를 찾는 데 사용되고 학습시키지는 않지만 학습에 관여하는 data가 validation data이다.
또한 Epoch 뿐만 아니라 hyperparameter나 hidden layer를 조정할 때도 사용될 수 있다.
+ ) overfitting, underfitting
'머신러닝, 딥러닝 > 기초' 카테고리의 다른 글
| [머신러닝 시스템의 종류] 지도학습/비지도학습/준지도학습/강화학습 (0) | 2022.02.16 |
|---|---|
| 주성분 분석(PCA)를 이해해보자 (1) | 2021.02.17 |

